首页
博客
理论工具
数据分析
spss分析
amos分析
python数据分析
结构方程模型
回归与中介
论文写作
未分类
数据服务
关于我们
0
个人中心
我的订单
退出
登录
登录
注册
Get Started
线性回归描述
在进行线性回归之前,首先需要对数据进行查看基本关系,然后进行检验数据是否满足参与\[线性回归分析\]的查看。 ### 1.相关关系 在\[回归分析\]前一般需要做相关分析,因为有了相关关系,才可能有回归影响关系;如果没有相关关系,是不应该有回归影响关系的。所以进行初步查看,结果如下: 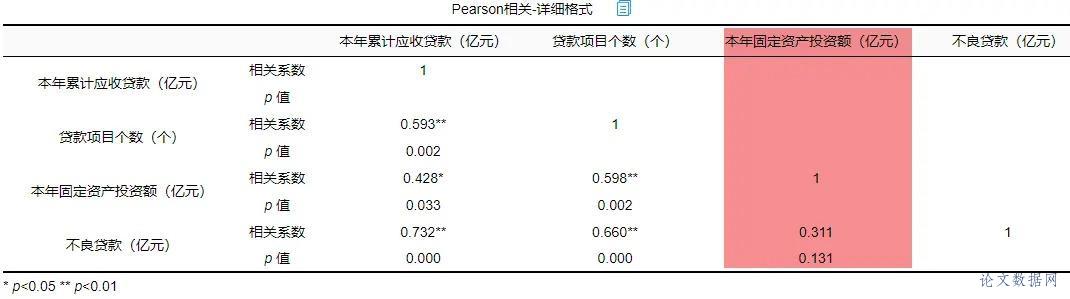 将“本年累计应收贷款”、“贷款项目个数”、“本年固定资产投资额”以及“不良贷款”之间进行两两相关分析。除了“本年固定资产投资额”和“不良贷款”之间p值大于0.05,其余两两之间分析p值均小于0.05,所以不良贷款与本年固定资产投资额没有相关关系,也即说明进行回归分析时不放入本年固定资产投资额。接下来查看数据是否存在共线性。 ### 2.共线性 共线性是指\[线性回归模型\]中的解释变量之间由于存在精确相关关系或高度相关关系(例如\[相关系数\] 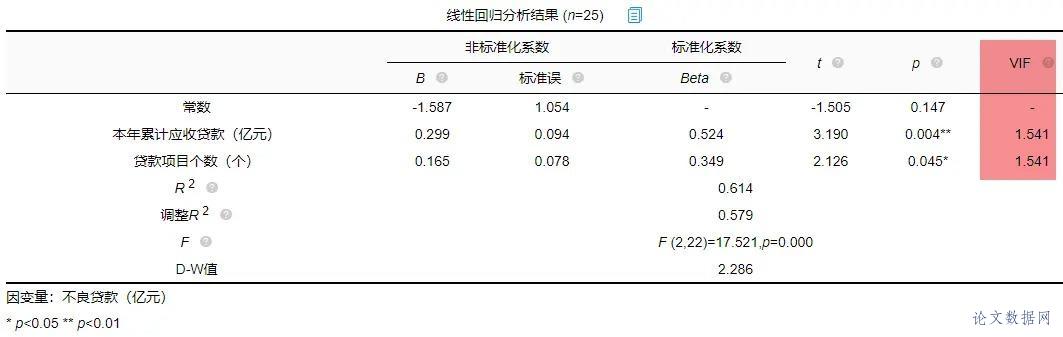 一般\[VIF值\]大于10(严格来说大于5),存在共线性问题,从分析结果中可以看到VIF值小于10,所以不存在共线性,如果存在共线性问题则不能使用线性回归,可以使用岭回归、\[Lasso回归\]等进行分析。 ## 四、前提条件检验 大多数方法进行分析时,都有假设或者分析的前提条件,线性回归也不例外。线性回归分析的前提条件概括为四个:线性、独立、正态和方差齐性,接下来一一检验。 ### 1.线性 一般检验数据之间的线性关系,是为了考察因变量随自变量值变化的情况,可以做相关分析从侧面进行说明或者利用\[散点图\]进行说明,散点图更加直观,所以本次选择散点图进行描述(\[SPSSAU\]可视化→散点图)。结果如下: 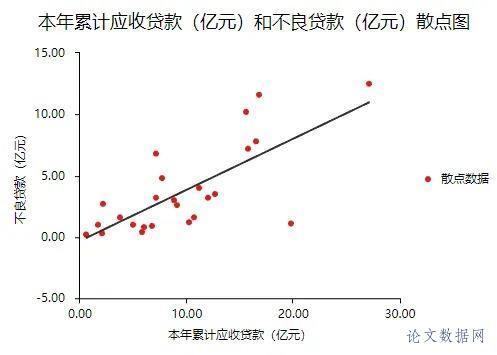 以“不良贷款(亿元)”作为Y轴,“本年累计应收贷款(亿元)”作为X轴建立散点图,发现“不良贷款(亿元)”与“本年累计应收贷款(亿元)”为线性关系。以同样的方法对“贷款项目个数”和“不良贷款”建立散点图,也存在线性关系。 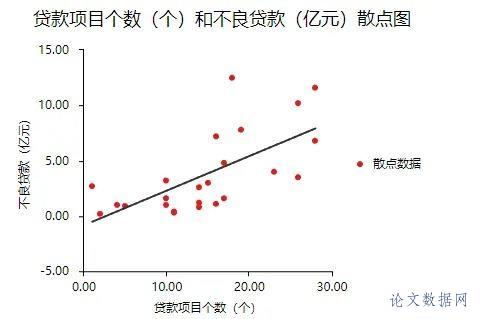 如果不呈现线性关系可以尝试通过变量变换进行修正,常用的变量变换的方法有对数变换、倒数变换等等。 ### 2.独立 独立是指残差是独立的。特别是,\[时间序列数据\]中的连续残差之间没有相关性。可以查看\[DW值\],一般在DW值在2附近(比如1.7-2.3之间),则说明没有\[自相关性\],模型构建良好,反之若DW值明显偏离2,则说明具有自相关性,模型构建较差(一般如果不是时间序列数据也可以不用过度关注)。尝试构建回归分析模型发现DW值为2.286。 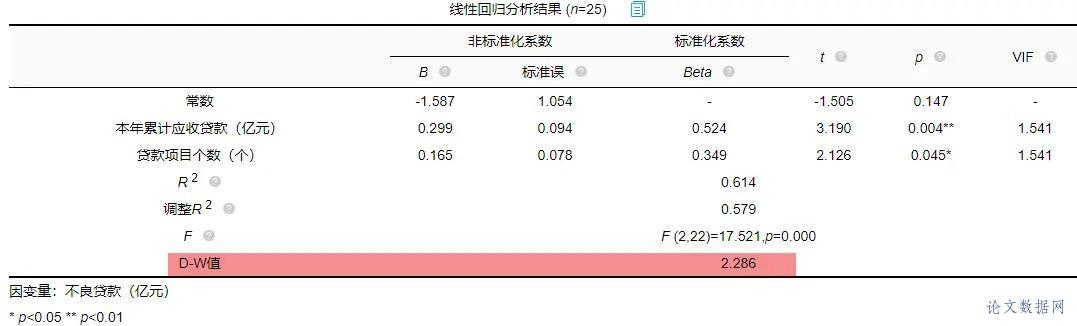 从结果中可以看出DW值为2.286在2的附近,表示模型构建良好。接下来进行验证“正态”。 ### 3.正态 正态表示残差服从正态分布。其方差σ2 = var (ei)反映了回归模型的精度,一般 σ 越小,用所得到回归模型预测y的精确度越高。建立回归分析模型得到残差与预测值,利用残差绘制直方图查看残差是否满足正态分布,结果如下: 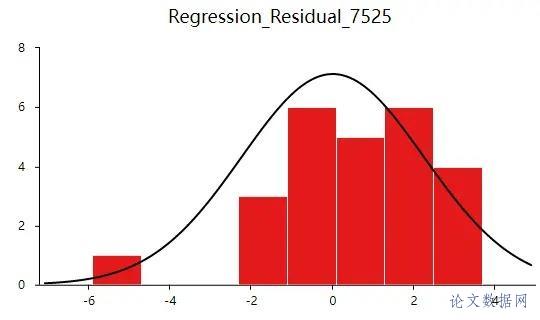 如果直方图呈现‘中间高,两边低,左右基本对称的 “钟形图”则基本服从正态分析,但是数据量过少等也可能影响结果导致很难呈现出标准的正态分布,如果是这种情况如果看见‘钟形’也可以可以接受的。上图可以看出,数据呈现的分布并不对称,但是也出现近似‘钟形’曲线,所以也可以接受。残差满足正态分布,接下来验证方差齐性。 ### 4.方差齐性 方差齐性是指残差的大小不随所有变量取值水平的改变而改变,即方差齐性。那么如何进行呢?首先对残差和预测值进行标准化,与标准化残差为Y轴,标准化预测值为X轴绘制散点图,如果所有点均匀分布在直线Y=0的两侧,则可以认为是方差齐性,结果如下: 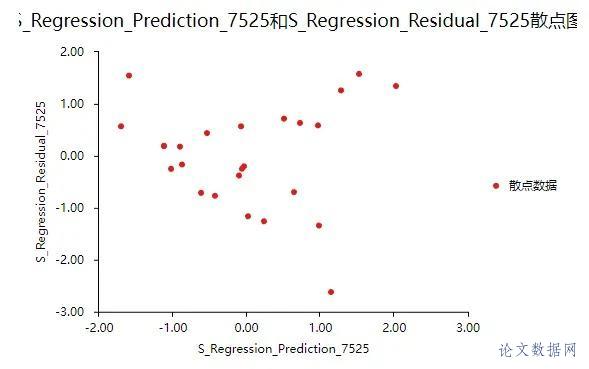 从散点图可以发现数据大致均匀分布在Y=0的两侧,所以可认为是方差齐性,综上,数据满足回归分析的前提假设。可以进行线性回归。 ## 五、回归分析 由上述分析与检验最后以“不良贷款(亿元)”为因变量,“本年累积应收贷款(亿元)”和“贷款项目个数(个)”为自变量构建线性回归模型。分析将从模型效果以及模型结果两部分进行说明。 ### 1.模型效果说明 模型效果说明包括F检验以及模型\[拟合优度\]。 **F检验**  F检验主要是观测\[被解释变量\]的线性关系是否显著,上表可以看出,进行回归方程的显著性检验时,统计量F=17.521,对应的p值小于0.05,所以说明被解释变量的线性关系是显著的,可以建立模型。那么模型的拟合优度又是怎么样的?接下来进行说明。 **拟合优度**  模型拟合优度一般查看R方值(\[决定系数\],模型拟合指标),如果R方为0.3代表自变量可以解释因变量30%的变化原因,一般越接近1说明拟合越好,但是很多研究中不会过多关注其大小,原因在于多数时候我们更在乎X对于Y是否有影响关系。从上表可以看出,模型R方值为0.614,调整R方为0.579。调整R方也是模型拟合指标。当x个数较多是调整R²比R²更为准确。 意味着“本年累积应收贷款(亿元)”和“贷款项目个数(个)”可以解释“不良贷款”61.4%变化原因。可见,模型拟合优度良好,说明被解释变量可以被模型大部分解释。接下来对模型结果进行解释。 ### 2.模型结果解释 管理者想要知道“本年累积应收贷款”、 “贷款项目个数”以及“本年固定资产投资额”对“不良贷款”是否有影响,如果有影响,它们之间谁的影响更大?因为前面的相关分析中得到了“本年固定资产投资额”与“不良贷款”之间没有相关关系,一般情况下没有相关关系是没有影响关系的,所以分析“本年累积应收贷款”、 “贷款项目个数”对“不良贷款”的影响关系,模型结果分为“是否有影响”以及“影响程度”进行阐述。首先查看自变量对因变量是否有影响。 **是否有影响** 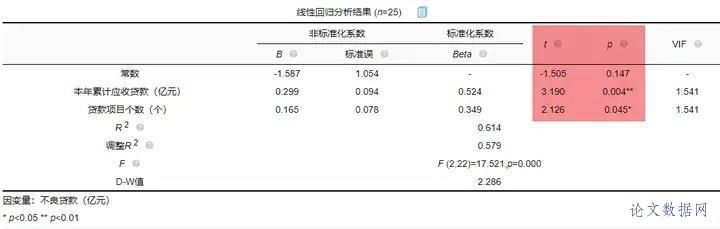 从上表可以看出,本年累计应收贷款分析项的t值为3.190,p值小于0.05说明此项具有显著性,即本年累计应收贷款对不良贷款有影响,贷款项目个数分析项的t值为2.126,p值小于0.05也说明此项具有显著性,即贷款项目个数对不良贷款有影响,二者对不良贷款有影响,具体谁影响大接下来进行说明。 **影响程度** 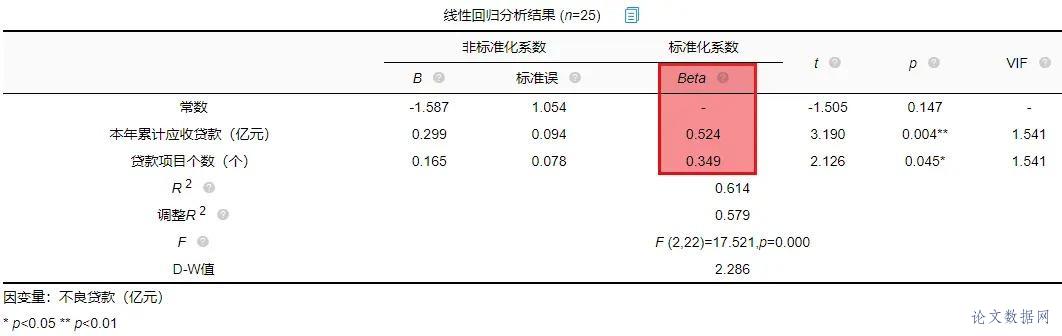 一般有影响关系才会去比较影响程度大小,影响程度大小需要查看标准化系数,标准化系数的绝对值越大表明自变量对因变量的反应越大,即影响程度越大,从上表中可以看出0.524>0.349,说明本年累积应收贷款相比较贷款项目个数对不良贷款影响更大。 除此之外,如果利用回归分析进行预测等,可以使用非标准化系数进行构建模型公式,具体不在赘述,可以进入SPSSAU官网进行查看。 ## 六、总结 利用线性回归对管理者的问题进行分析,首先对数据的进本关系进行查看以及探索数据是否满足线性回归分析的条件,对数据处理后进行线性回归分析,发现“本年累积应收贷款”、 “贷款项目个数”对“不良贷款”有影响,并且查看标准化系数发现“本年累积应收贷款”影响程度更大,这对于管理者后续分析提供了有效信息。分析完毕。
2024-09-13 16:37 by admin
52
0
热门文章
1
clashX 设置白名单,忽略本地hosts测试域名的代理设置。
2
验证性因子分析步骤以及应达到的标准
3
Spss详细图文教程——问卷信度和效度检验步骤图解
4
信度效度分析的注意事项
5
MATLAB时代的七种开源替代方案