首页
博客
理论工具
数据分析
spss分析
amos分析
python数据分析
结构方程模型
回归与中介
论文写作
未分类
数据服务
关于我们
0
个人中心
我的订单
退出
登录
登录
注册
Get Started
分层线性回归
SPSS案例实践:控制变量与分层线性回归 有读者觉得*分层回归*很神秘,哪怕是做过*多元线性回归*,也不知道分层回归是做什么,怎么做。 ## 01 案例背景介绍 本来我是要研究有用性、易用性、趣味性对总体满意度的影响,但是我阅读论文发现,再加上我做显著性检验提示,不同年龄、不同职业读者对公号的满意度有统计学差异。 所以,我想**控制*年龄、职业*,来考察一下有用性、易用性、趣味性对总体满意度的影响**。 ## 02 分层线性回归 打开SPSS线性回归对话框,**因变量**是总体满意度,第一层就安排控制变量,包括年龄和职业,是分类的 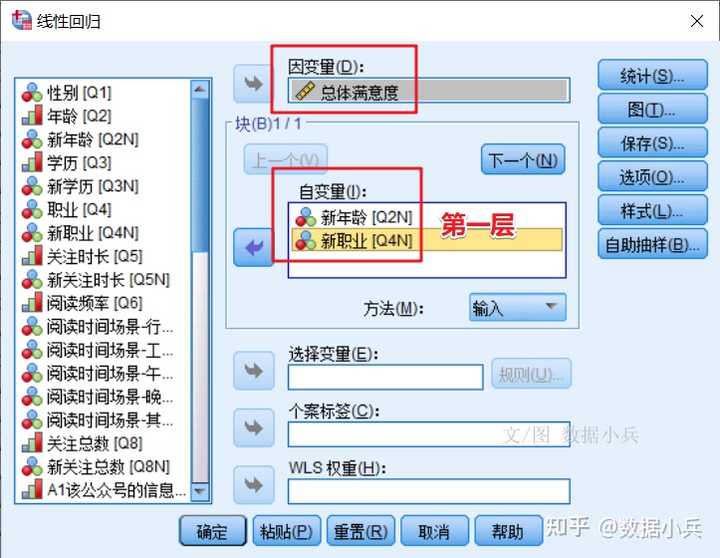 按【下一个】按钮,第二层自变量咱们一次把三个重点关注自变量**有用性、易用性、趣味性**一把扔进去。 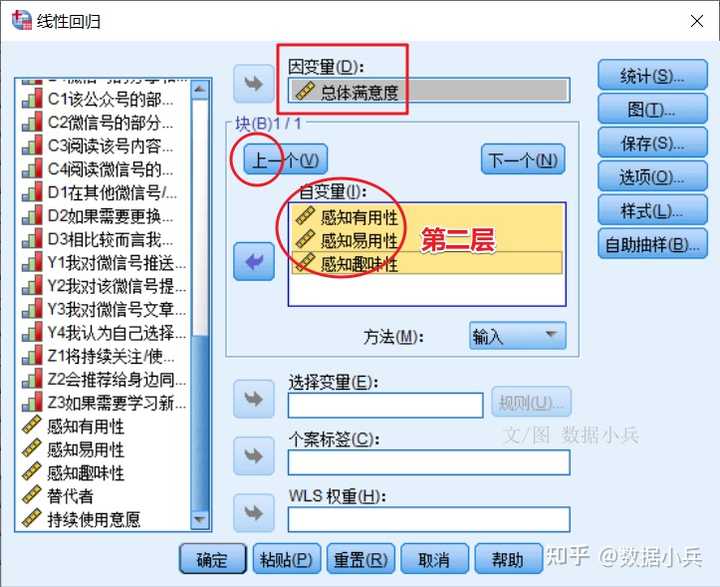 在统计学上,控制变量也是自变量。控制变量仅是从研究层面出发的一种对自变量的称呼。 自变量按照不同层来安排,层在这里不好理解,字面的感觉是第一层是第一层,第二层是第二层,但其实不然。 实际回归过程只有一个桶,人为把桶划分为几个层,比如本例就是划分为两层,先把年龄+职业放最底下一层,马上做一次回归,得到第一层的[回归模型],然后接着(叠加)继续往这个桶里面装自变量有用性,易用性、趣味性,这是第二层,但此时整个桶里面已经有2+3=5个自变量了,再做第二层回归得到模型2。 模型1到模型2的变化是,在(年龄+职业)基础上多了(有用+易用+有趣)。 有一个关键之处提示一下:分层回归时,自变量进入模型的方式应该为enter法,不能是其他方式,软件默认就是enter法。 ## 3 输出R方变化量 打开【统计】对话框,务必勾选上【R方变化量】,这是关键输出的结果,也是体现做分层回归之意义所在的结果。 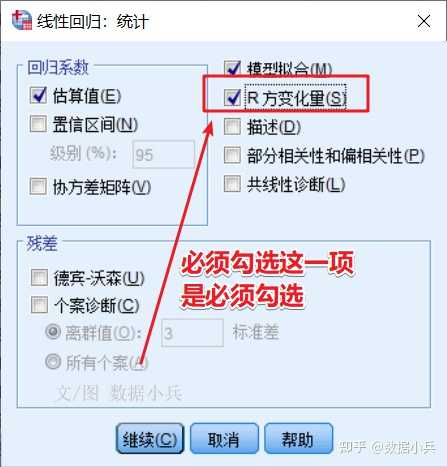 R方就是自变量对因变量变异的解释比例,所谓“变化量”就是`代尔塔Δ`,第二层与第一层的自变量们,他们对Y的影响之`R方`改变的情况。 其他回归的参数选项,就按软件默认或按照普通线性回归来安排即可。 ## 04 结果的解读 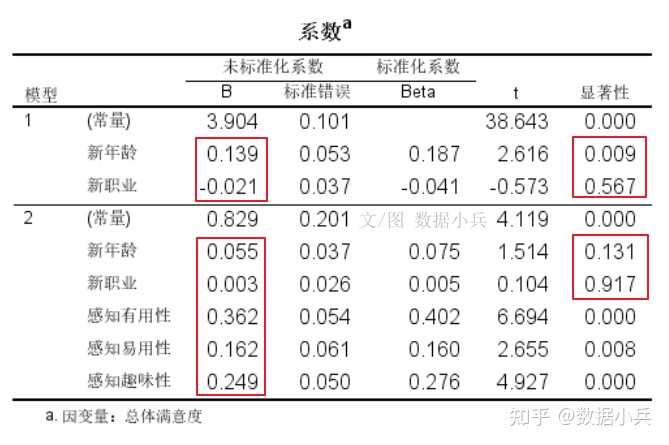 前后两个模型的偏[回归系数]及显著性检验结果。 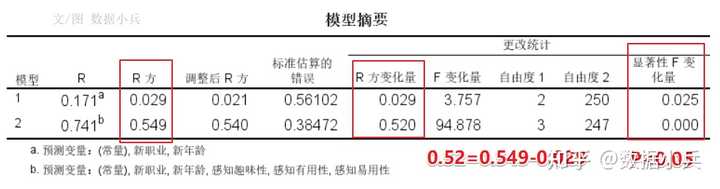 前后两个模型R方及R方变化量,还有变化量的显著性检验。 这结果怎么看? 首先模型1和模型2都是有统计学意义的(F1=3.757,F2=60.123,P1=0.025,P2 \<0.001)。(表格略) 然后就看这个R方变化吧。(年龄+职业)为自变量时,R方=0.029,虽然与没有自变量的模型相比有统计学意义(P=0.025),但R方不怎么高,模型1解释能力偏低。 (年龄+职业+有用+易用+有趣)为自变量时,R方=0.549,0.549之于0.029,增加了多少呢?Δ=0.52,增加了五成的解释能力,是谁带来的呢,是(有用+易用+有趣)的共同作用。这种增加量有没有统计学意义呢?答案是有意义(F=94.878,P \< 0.001)。 说明啥?说明我们重点关注的(有用+易用+有趣)真的是找对方向了,对其的关注是明智的,他们对Y的影响很大。 ## 05 结果的展示 分层回归的结果,不要直接搬用SPSS默认输出的几个表格,分散且不好安排排版。我们需要将几个表格编辑整理为一个表格。常见的形式如下: 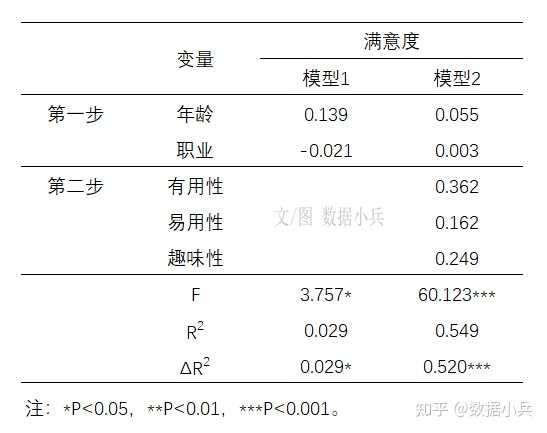 大家拿这个表格,对照上面的文字解读,再次去理解分层回归。 总结一句:分层回归,自变量是一层一层叠加上去的,为的就是看每增加一个或多个自变量后模型的改变有没有统计学意义,本质上是专门研究后来居上的新增自变量的重要性。
2024-09-20 17:55 by admin
69
0
注:本文转载自https://www.zhihu.com/question/641675932/answer/3424881700,如有侵权行为,请联系我们,我们会及时删除。
热门文章
1
clashX 设置白名单,忽略本地hosts测试域名的代理设置。
2
验证性因子分析步骤以及应达到的标准
3
Spss详细图文教程——问卷信度和效度检验步骤图解
4
信度效度分析的注意事项
5
MATLAB时代的七种开源替代方案